Pipeline-For-NLP-With-Blooms-Taxonomy
Pipeline For NLP with Bloom’s Taxonomy Using Improved Question Classification and Question Generation using Deep Learning
This repository contains all the source code that is needed for the Project : An Efficient Pipeline For Bloom’s Taxonomy with Question Generation Using Natural Language Processing and Deep Learning.
Outline :
An examination assessment undertaken by educational institutions is an essential process, since it is one of the fundamental steps to determine a student’s progress and achievements for a distinct subject or course. To meet learning objectives, the questions must be presented by the topics, that are mastered by the students. Generation of examination questions from an extensive amount of available text material presents some complications. The current availability of huge lengths of textbooks makes it a slow and time-consuming task for a faculty when it comes to manually annotate good quality of questions keeping in mind, they are well balanced as well. As a result, faculties rely on Bloom’s taxonomy’s cognitive domain, which is a popular framework, for assessing students’ intellectual abilities.
Therefore, the primary goal of this research paper is to demonstrate an effective pipeline for the generation of questions using deep learning from a given text corpus. We also employ various neural network architectures to classify questions into the cognitive domain of different levels of Bloom’s taxonomy using deep learning, to derive questions and judge the complexity and specificity of those questions.
The findings from this study showed that the proposed pipeline is significant in generating the questions, which were equally similar concerning manually annotated questions and classifying questions from multiple domains based on Bloom’s taxonomy.
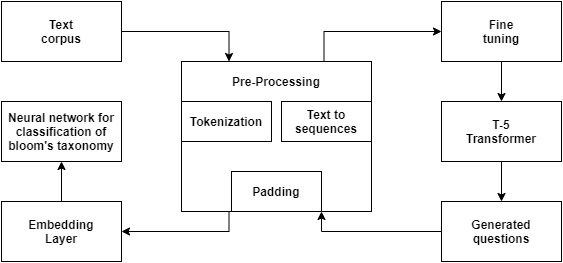
Main Proposed Pipeline Layout :
Used Datasets
Squad Dataset 2.0 - Used In Question Generation Module. Released in 2018, has over 150,000 question-answer pairs.
"Yahya et al, (2012)" Introduced Dataset - Dataset Used in Question Classification Module.Consists of around 600 open-ended questions, covering a wide variety of questions belonging to the different levels of the cognitive domain. Original Dataset required some basic pre-processing and then manually converted into dataframe. Check out main paper cited here.
Quora Question Pairs Dataset- Dataset Used in Case study of computing semantic similarity between generated questions from T5 Transformer and manually annotated questions from survey form.
Question Generation Module:
The dataset being used for the question generation is Squad
(The Stanford Question Answering Dataset) 2.0 Dataset.
Squad 2.0 is an extension of the original Squad V1.1 that
was published in 2016 by Stanford University.
In this paper, we have implemented T5 Transformer, which is then fine-tuned using PyTorch lightning and training it on the Squad 2.0 dataset. T5 is
essentially an encoder-decoder model which takes in all
NLP problems and has them converted to a text-to-text
format.
Table 1
| Passage | Answer Context |
|---|---|
| The term health is very frequently used by everybody. How do we define it? Health does not simply mean "absence of disease" or "physical fitness". It could be defined as a state of complete physical, mental and social well-being. When people are healthy, they are more efficient at work. This increases productivity and brings economic prosperity. Health also increases longevity of people and reduces infant and maternal mortality. When the functioning of one or more organs or systems of the body is adversely affected, characterized by appearance of various signs and symptoms,we say that we are not healthy, i.e., we have a disease. Diseases can be broadly grouped into infectious and non-infectious. Diseases which are easily transmitted from one person to another, are called infectious diseases.' | Easily transmitted from one person to another |
| Proteins are the most abundant biomolecules of the living system. Chief sources of proteins are milk, cheese, pulses, peanuts, fish, meat, etc. They occur in every part of the body and form the fundamental basis of structure and functions of life. They are also required for growth and maintenance of the body. The word protein is derived from Greek word, “proteios” which means primary or of prime importance. | Greek Word |
Table 1 shows the passages that we have input it into the model and the answers that we want the questions to be generated. We have taken these passages from various high school level books.
Table 2
| Answer Context | Easily transmitted from one person to another | Greek Word | |
|---|---|---|---|
| Questions Generated | How are infectious diseases defined? | What does the word protein come from? | |
| Questions Received | What do you mean by infectious disease? | What is "proteios"? From which language was it derived from? |
As you can see in table 2, the questions generated row are the questions generated as per the answer context by our model.
Correspondingly, the Questions Received are the ones that we obtained from circulating a survey that contained the same passage and context.
Results
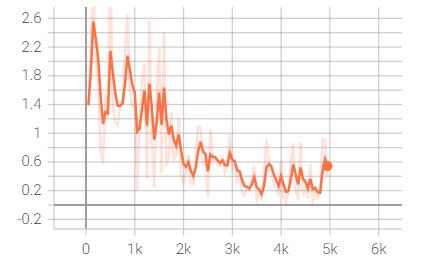
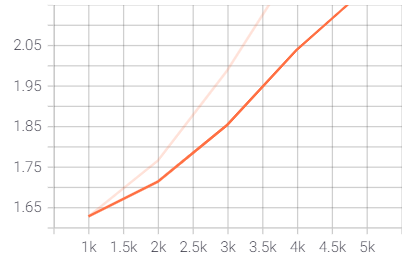
After training, we observed a steady decrease in training loss Fig. 3. The validation loss fluctuated and has been observed in Fig. 4. Note that due to fewer computation resources, we could train for only a limited amount of time, and hence the fluctuations in validation loss.
Training Loss = 0.070
Validation Loss = 2.39
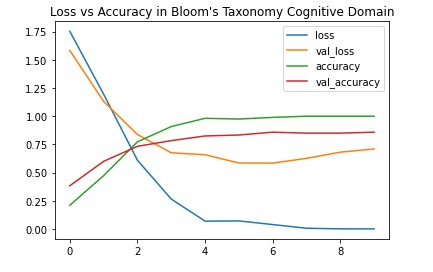
Question Classification Module :
A deep learning-based model for multi class classification which takes in a text as input and tries to classify a certain category out of multiple categories in coginitive domain of bloom’s taxonomy.
Dataset Used : Yahaa et all (2012)
Model Pipeline :
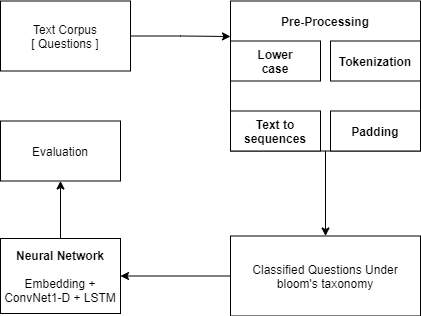
Model Architecture :
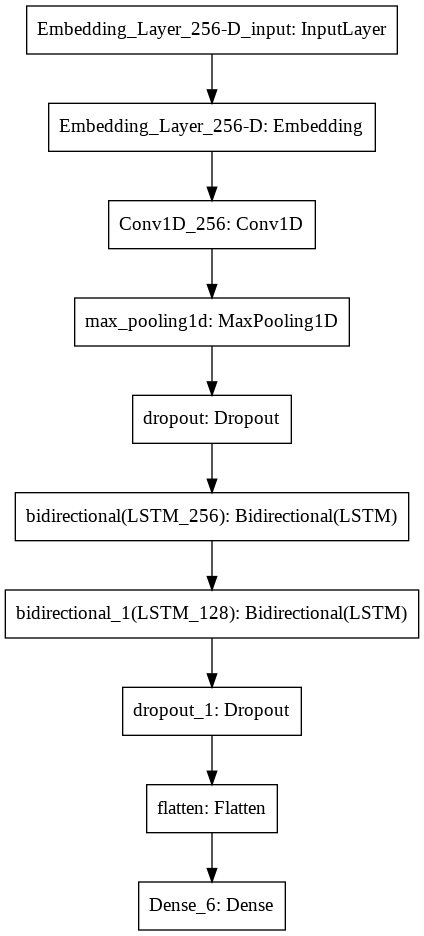
Results :
Summarised Evaluation :
| S.No | Model | Optimizer | Accuracy | Loss | Dropout |
|---|---|---|---|---|---|
| 1 | ConvNet 1D+ 2 Bidirectional LSTMs Layers | Adam | 80.83 | 0.6842 | |
| 2 | ConvNet 1D+ 2 Bidirectional LSTMs Layers | RMSProp | 80.00 | 1.50 | |
| 3 | ConvNet 1D+ 2 Bidirectional LSTMs Layers | Adam with ClipNorm=1.25 | 83.33 | 0.86 | |
| 4 | ConvNet 1D+ 2 Bidirectional LSTMs Layers | RMSProp with ClipNorm=1.25 | 79.17 | 2.10 | |
| 5 | ConvNet 1D+ 2 Bidirectional LSTMs Layers | Adam | 86.67 | 0.59 | Recurrent Dropout=0.1 |
| 6 | ConvNet 1D+ 2 Bidirectional LSTMs Layers | RMSprop | 78.83 | 2.54 | Recurrent Dropout=0.1 |
| 7 | ConvNet 1D+ 2 Bidirectional LSTMs Layers | Adam with ClipNorm=1.25 | 85.83 | 0.56 | Recurrent Dropout=0.1 |
| 8 | ConvNet 1D+ 2 Bidirectional LSTMs Layers | RMSprop with ClipNorm=1.25 | 75.83 | 0.76 | Recurrent Dropout=0.1 |
| 9 | ConvNet 1D+ 2 Bidirectional LSTMs Layers + GloVe 100-D | Adam With ClipNorm=1.25 | 73.33 | 1.28 | |
| 10 | ConvNet 1D+ 2 Bidirectional LSTMs Layers + GloVe 300-D | Adam With ClipNorm=1.25 | 75.83 | 0.88 | |
| 11 | ConvNet 1D+ 2 Bidirectional LSTMs Layers + GloVe 100-D | RMSprop With ClipNorm=1.25 | 73.33 | 2.31 | |
| 12 | ConvNet 1D+ 2 Bidirectional LSTMs Layers + GloVe 300-D | RMSprop With ClipNorm=1.25 | 80.00 | 1.12 |
The Best Performance was exhibited by the following dense neural network :
ConvNet 1D with 2 Bidirectional LSTMs Layers ,along with Adam optimizer and recurrent dropout =0.1 as regulariser.
Following Results were obtained :
Accuracy : 86.67 %
Loss : 0.59
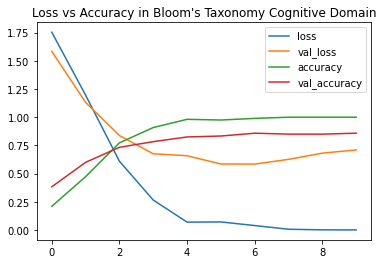
Accuracy vs Loss Plot :
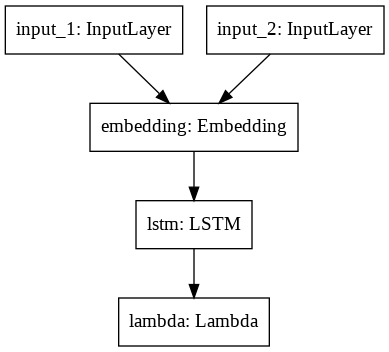
Siamese Neural Network for Computing Sentence Similarity – A Case Study :
With a thorough analysis of the outputs, i.e., questions, generated from the proposed model,a case study was done to evaluate how much the generated questions are semantically similar to the questions if annotated manually. For this evaluation, we considered an effective pipeline of Siamese neural networks. This study was done in order to explore insights about the effectiveness of our proposed pipeline – how much our model is efficient to generate questions when compared to the manual annotation of the questions which requires comparatively more hard work and time.
Model Architecture :
| Generated Questions | Manually Annotated Questions | Context | Similarity Score |
|---|---|---|---|
| Why is health more efficient at work? | How does health affect efficiency at work? | Increases Productivity And Brings Economic Prosperity | 0.4464 |
| What is the health of people more efficient at work? | What are the outcomes of being more efficient at work as a result of good health? | Increases Productivity And Brings Economic Prosperity | 0.4811 |
| What is the term infectious disease? | What do you mean by infectious disease? | Easily Transmitted From One Person To Another | 0.3505 |
| How are infectious diseases defined? | Define infectious disease. | Easily Transmitted From One Person To Another | 0.2489 |
| According to classical electromagnetic theory, an accelerating charged particle does what ? | According to electromagnetic theory what happens when a charged particle accelerates ? | Emits Radiation In The Form Of Electromagnetic Waves | 0.2074 |
| What does the theory of an accelerating charged particle imply ? | What does the classical electromagnetic theory state ? | Emits Radiation In The Form Of Electromagnetic Waves | 0.0474 |
| What was the Harappans's strategy of sending expeditions to ? | What was the primary reason for settlements and expeditions as seen from Harappans's ? | Strategy For Procuring Raw Materials | 0.4222 |
| What was the idea behind sending expeditions to Rajasthan ? | Why did the Harappans's send expeditions to areas in Rajasthan ? | Strategy For Procuring Raw Materials | 0.6870 |
| What was a feature of the Ganeshwar culture ? | What was the distinctive feature of the Ganeshwar culture ? | Non-Harappan Pottery | 0.6439 |
| What type of artefacts are from the Ganeshwar culture ? | What kind of artefacts are from Ganeshwar culture ? | Non-Harappan Pottery | 0.4309 |
| Proteins form the basis of what? | What is the significance of proteins ? | Function Of Life | 0.1907 |
| What are proteins the fundamental basis of ? | What does protein form along with fundamental basis of structure ? | Function Of Life | 0.1775 |
The above analysis is a sample from a set of recorded observations evaluated by our network. This clearly indicates the depth of similarity score between generated questions from the transformer and manually annotated questions from the survey.
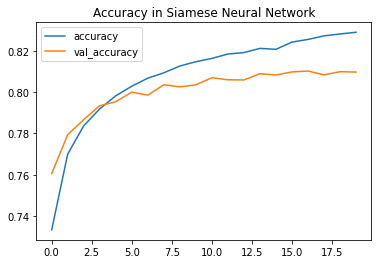
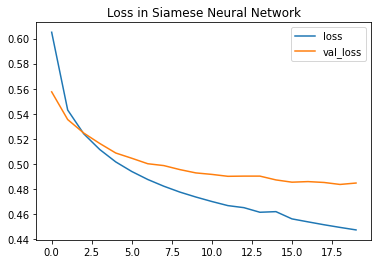
Accuracy vs Loss Plot :
GitHub
https://github.com/RohanMathur17/Pipeline-For-NLP-With-Blooms-Taxonomy